




















ALLDATA
It’s every email marketer’s worst nightmare. A sudden spike in bounce rates. Luckily, ALLDATA had Act-On’s deliverability team on their side.

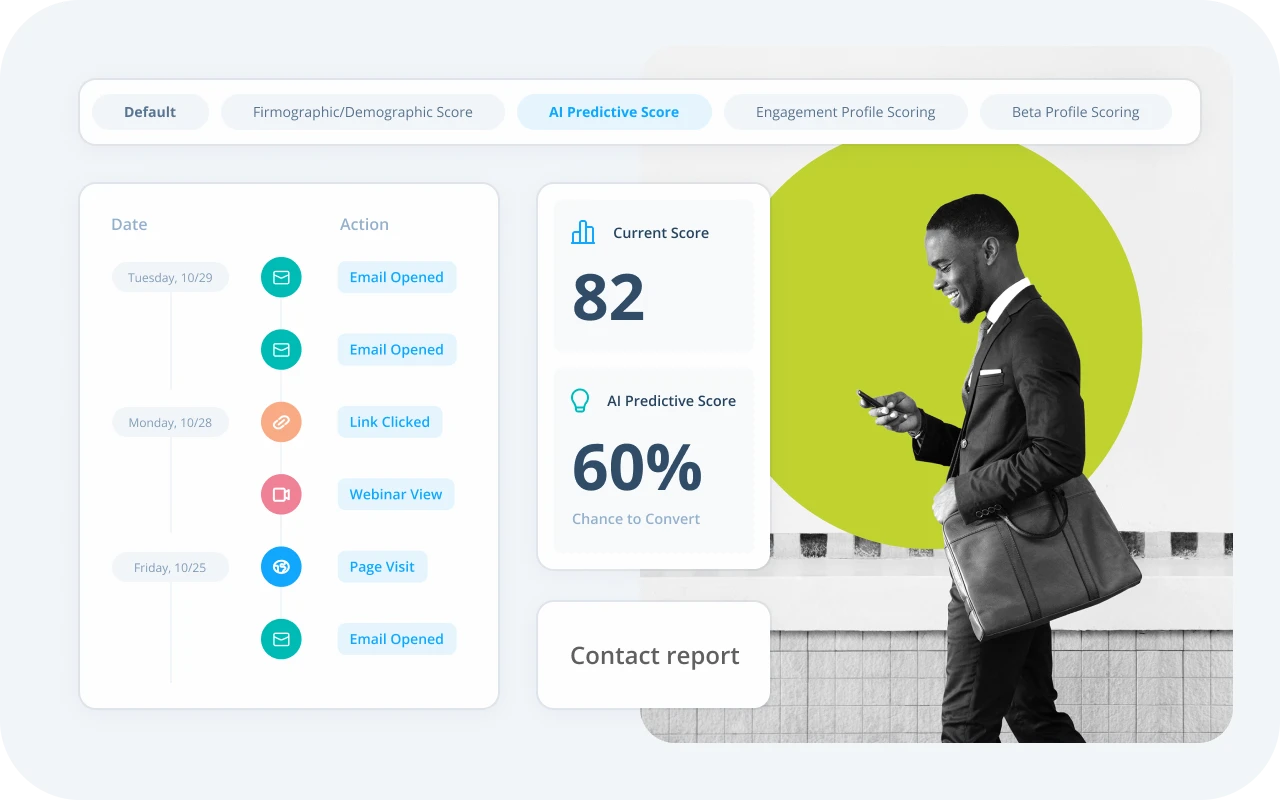
What is Lead Scoring for Marketing and What Are the Benefits?
Lead scoring helps organizations move prospects along their buying journey in a structured, strategic way — which is especially helpful considering how complex buying journeys have become.

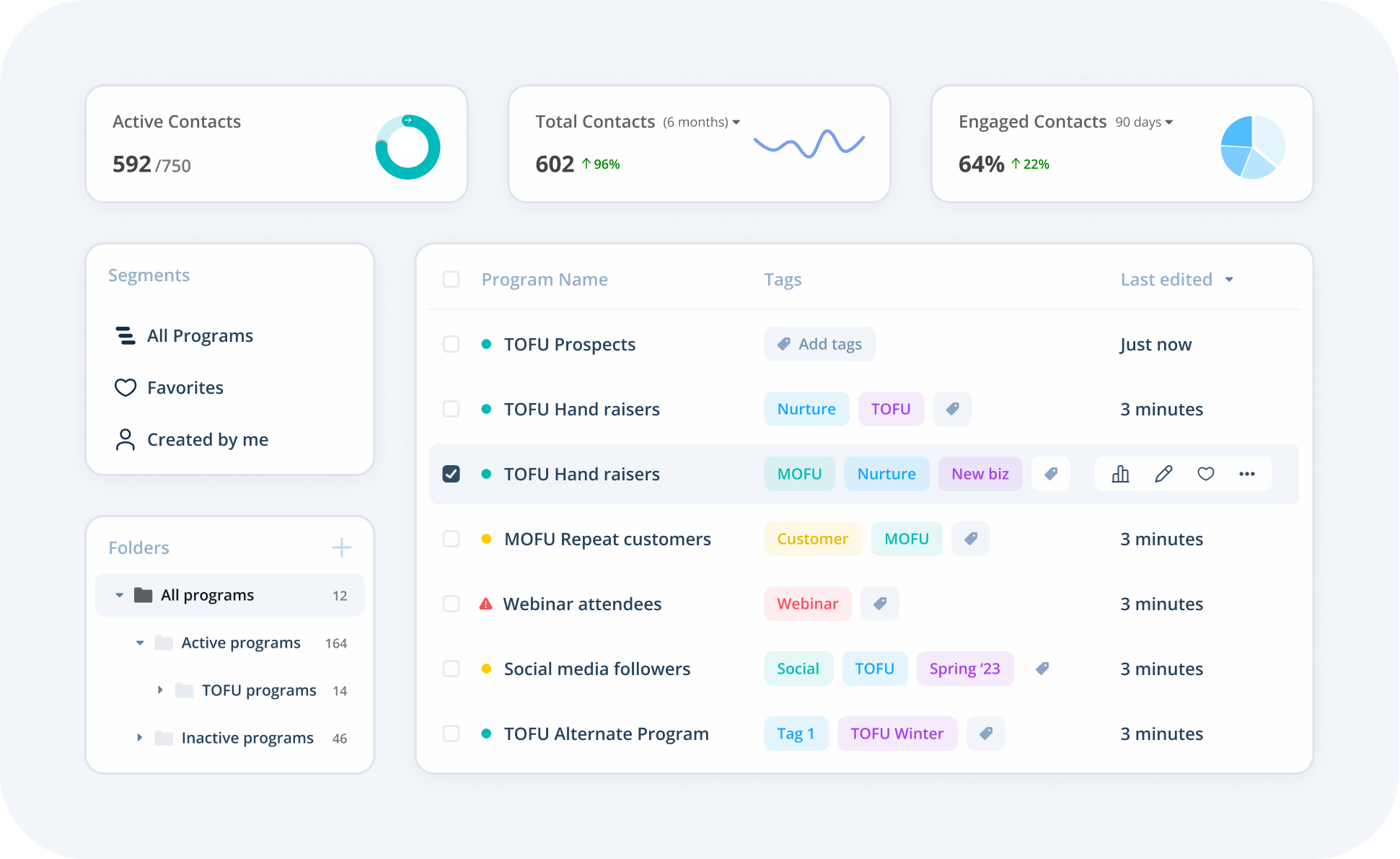
Crafting A Modern Lead Story: Strategies for Effective Lead to Pipeline Conversion
We all know the classic tale: Lead meets brand. They’ve been burned by broken promises before, but this time feels different. The brand’s products solve



